Setting Up SQL Replication from On-Prem/EC2 to RDS
SQL Transactional Push Replication Setup
There is this wonderful blog post in AWS Database Blog, “How to migrate to Amazon RDS for SQL Server using transactional replication”, which talks about how to setup a push transactional replication to move data from a SQL server, which is on an EC2 instance or in your on-prem servers, to AWS RDS database. The instructions are very clear and talks about when to use this approach and the pitfalls.
I was exploring this option at work to migrate data from a SQL Server DB in EC2 to RDS. Ideally, I wanted a continuous replication but from the AWS blog post it was clear that I should not be doing that since the RDS computer name can change during failover or host replacement in a Multi-AZ RDS setup. But I wanted to try and proceed with this option anyway, at least to see how easy it is to do one-time loads with SQL replication instead of using DMS.
Issue
I followed the AWS blog post and completed setting up the distributor, publisher, security groups on RDS, and few other things. But then I faced a problem in the middle of the setup.
When the time came to create a New Subscription, going through the screens,
I got an error. The AWS blog post specifically talks about this error and says
this is expected. Below is the screenshot they had in the post.
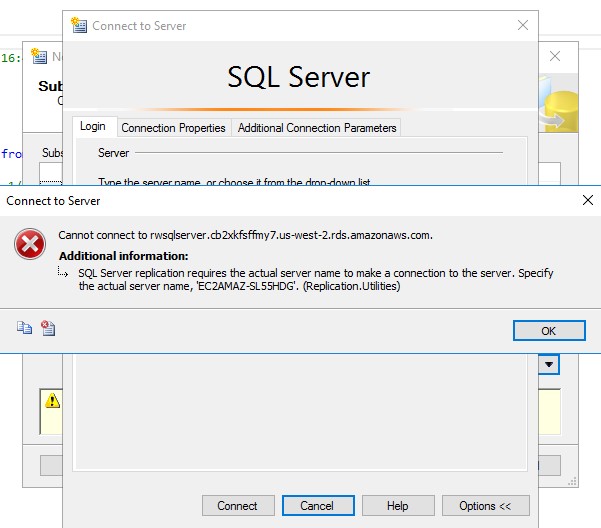
My problem was that I didn’t exactly get this error. I got a slight variation of this that looked like below.
Cannot connect to xxxx.us-east-1.rds.amazonaws.com.
Additional Information:
SQL Server replication requires the actual server name to make a connection to the server.
Specify the actual server name, ‘‘. (Replication.Utilities)
See the difference? The server name inside the single quotes in the error above is empty in my case compared to the screenshot.
The error I got is not that different from the original so I went ahead and followed the resolution which was in the blog. The resolution to the problem was that we can’t use RDS cname when setting up the subscriber. Instead, the computer name of the RDS instance has to be used in subscriber connection properties.
In the AWS blog post, the server name was conveniently returned from the error message, but not in my case. You can get the computer name of RDS instance by issuing the following query against the RDS database.
SELECT @@SERVERNAME
After you get the server name, you can’t just paste this in connection dialog
box. You have to define a DNS entry for this in your hosts file. This is also
shown in the AWS blog post so I followed the same process.
I recycled SQL service on my EC2 instance and went through setting up the subscription again. This time I got a different error. That’s unexpected. The AWS blog post didn’t talk about this. The empty server name that I got in the first error must be somehow related to this. The second error complained something about networks. Screenshot below.
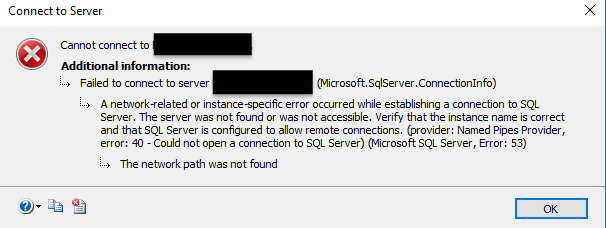
This error is obvious. SQL server is not able to reach the target server (subscriber) for some reason. It could be firewall but I ruled this out pretty easily. The only difference in configuration between my systems and the blog post was that, in the AWS blog post RDS was running on the default MSSQL port which is 1433. I was not. For security reasons, my RDS was on a different port than the default. This could explain the error I’m getting and it did.
Resolution
Now that I kind of knew this could be the problem, I thought I could simply add the port number with the computer name (like EHDYSDS-SHD768, 14019) in the subscriber connection properties. Obviously this didn’t work as it can’t make sense of the hosts entry and just threw a ‘network path was not found’ error.
I then remembered about SQL aliases. You can do this by opening SQL Server
Configuration Manager > SQL Native Client 11.0 Configuration (32bit) > Aliases.
Aliases are cool because yon can setup an alias for your SQL server connection
so that you don’t have to enter a long cname and/or port number in every one of
your connection string on the computer where the SQL Alias is defined.
On the EC2 machine where I have my SQL server, using the SQL Server Configuration Manager, I defined a SQL alias with the RDS computer name aliased to its cname and my custom port. I used this alias in subscriber connection properties and my connection was a success! I proceeded with rest of the blog post and was able to prove out the push replication aspect of it.
Note: Just make sure you define aliases in both the 32-bit and 64-bit configuration settings so that depending on the client tool data type, the alias would take effect. For SQL replication 32-bit is good enough. You can also remove the hosts entry you added. That’s pretty useless once you define the alias.
